Revolution Pi
Choice of Programming Language:
- C#: This language was used in two main aspects of our system, it was used first to make an easy to use and efficient way of converting images to the correct format that the Viola Jones algorithm uses (24x24 grey-scale images), this was needed as the algorithm needs 1000s of faces and non-faces to correctly distinguish them and individually finding and formatting these images would be a time consuming task otherwise. C# was also used when interfacing between the Raspberry PI and computers, as we could easily allow serial communication with C# and so reliable communication between the two machines was possible which we needed to make our system as user friendly and easy to use as possible.
- C++: This is the workhorse of our system, C++ is used heavily in two aspects, to calculate the 160,000 or so features possible for around 10000 images (creating over 1 billion calculations overall just to classify each feature), and in the final analysis on the raspberry pi to detect faces, it was used in the bulk processing of features as it is by far the best language we could use for this job, as it incredibly efficient when handling large and similar data sets. We used it for the Raspberry PI as python was too slow and openGL (so GLSL) would not be easily available for both C and python so C++ was the obvious choice.
- Java: Here java was used as it had the ability to process images were C++ didn’t, as Java is very to c# many of the aspects talked about earlier also apply here, although not as fast as C++ would have been in creating the integral images Java not only aloud the correct reading of the file data but easier debugging which was vital as incorrectly processing thousands of images before having to simply reprocess them is incredibly time consuming. C# was not used here as there was not a need for visual forms to represent the processing of the data.
Libraries Used for this Project:
In order to allow the raspberry pi analyse the camera data from the separate camera module connected to the pi we decided to use an existing library. We decided to use the open source library situated at:http://robotblogging.blogspot.co.uk/2013/10/an-efficient-and-simple-c-api-for.html The purpose of this library was in order to read camera RGBA values from the Raspberry Pi’s memory and make it available in a simple array for later manipulation.
In the development stages of this project we also made use of the Raspberry Pi’s GPU when displaying any output we received from the camera feed for debugging processes. In order to do so we also made use of the open source openGL library, which included making use of the GLSL(OpenGL Shader Language) language with C++.
Introduction to Voila Jones:
The voila jones algorithm is a type of learning program used so that a program is able to learn what features to look for when trying to identify the presence of a face as opposed to having these parameters manually inputted and found by the user. However in order to achieve reliable results from this learning algorithm a database of several thousand images of faces and non faces will be needed.
In reality what the algorithm actually compares is the difference between sections of pixels in different regions of the image.
In order to best understand this algorithm the it must be separated into the following sections: Integral Image, Haar Features, Adaboost and Cascading
Integral image:
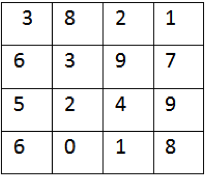
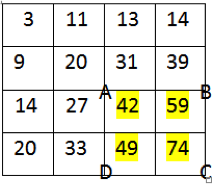
In order to speed up the process of finding the sum of a variable area of pixels
in an image, the starting input image is first converted to what is known as an integral image. An integral image is when each x and y coordinates RGB or in this case greyscale value is assigned the sum of the greyscale value of each of the x and y coordinates above and to the left of it.
These two images show the changes between an image array before and after being converted into an integral image array.
This example shows how an integral image can be used to find the value of the area of a defined region of pixels.
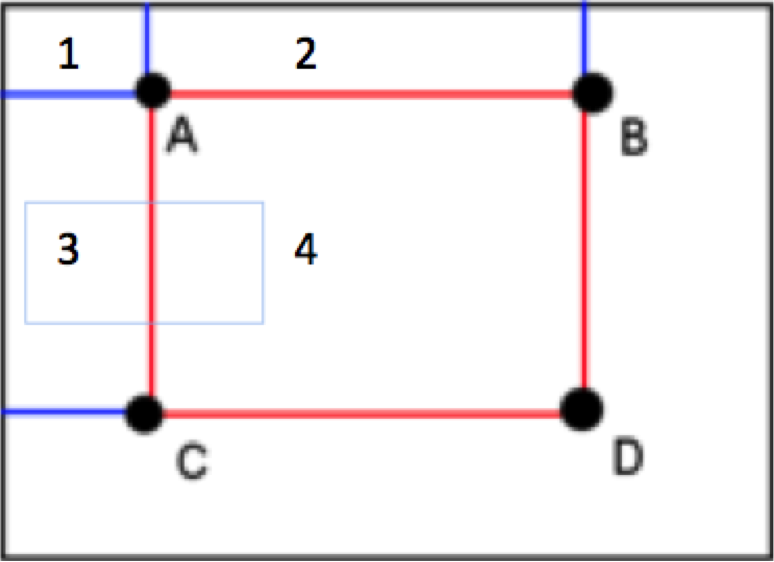
- A=1
- B=1+2
- C=1+3
- D=1+2+3+4
- =>D-B=(1+2+3+4)-(1+2)=3+4
- =>D-B-C=(3+4)-(1+3)=4-1
- =>D-B-C+A=4-1+1=4
This shows that using an integral image only requires 4 array references for each region of the image of any dimensions whereas when manually processing the image would require a considerable amount more. Making this feature one of the defining elements of the voila jones implementation that allows it to be a real time face tracking competitor.
Haar Features:


One of the reasons the Viola Jones algorithm is so fast is that it uses very simple features to identify faces, there are 5 of these in the default Viola Jones algorithm although some use more complex ones.
These features represent how to calculate a value within a certain region. This is done by calculating the sum of the pixels in the white regions and the sum of the pixels in the black, it then subtracts the black sum from the white sum to get a value. The Haar features shown above are just templates, they can be scaled and rotated and flipped meaning for a 24x24 image there are over 160,000 of these features we need to analyse and to properly train the algorithm we need 1000s of images of faces and not faces. Once values have been calculated for every feature on ever face and not face then we can begin to train the algorithm.
AdaBoost and Training Viola Jones:
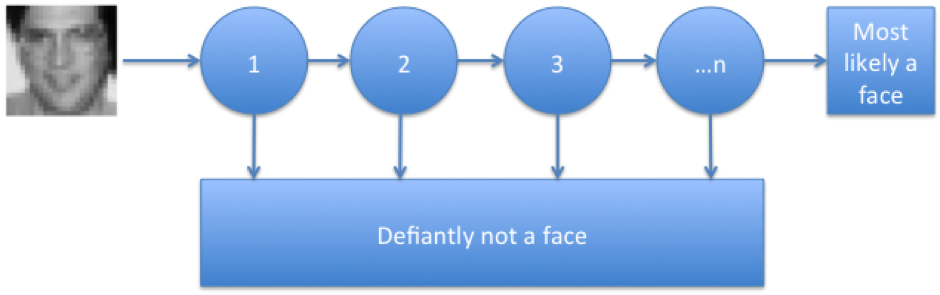
Once we have calculated values for every Haar feature on every image we need to use these values to identify faces. This is done by finding the boundaries that produces the least amount of false positives and false negatives, from here it sorts the Haar features into order of which ones were the best at identifying the faces and not faces, it then looks at the false positives and negatives of this feature, and looks for a feature that didn’t share the same errors in identifying faces, much like how a good team will counter the individuals weaknesses. Eventually we will have only a few faces and not faces being incorrectly identified by the group of features, this group of features is called a strong classifier.
This process of finding the false identifications and weighting them higher so it is more important the next feature chosen to add to the strong classifier will correctly identify them is called Adaboost.
The problem with the strong classifier is that it is very costly to run over an entire image every frame. In order to fix this we simply create what is called a cascade classifier.
A cascade Classifier is essentially breaking down the strong classifier into multiple steps, each one more complicated than the last. If at any point along the process the image is rejected by the classifier then it is defiantly not a face, if it makes it through it is most likely a face. The reason this is so much faster than just brute forcing the strong classifier is that the whole image is only analysed by the first step which is faster, and any bits that are defiantly not faces by it’s standards are rejected, meaning the next more complicated classifier has to analyse less, and the next one even less, so the strongest classifiers only have to analyse images that are almost defiantly faces. This cuts down on a lot of the wasted time processing the image as 90% of an image is not faces and so by removing most of that wastage we significantly speed up the analysis.